こんにちは!
今回は「PukiWiki」を「Docker」で見る手順をご紹介します。
きっかけ
きっかけは、2019年頃、長年利用していた無料Webホスティングの終了です。
終了により、公開していた私の個人メモ用サイト(「PukiWiki」を利用)も一緒に消滅しました。
サイトはまるごと消滅前に救出したので問題ないのですが、Web形式で見られないのは本当に不便です。
そこで、「Docker」のWindows版である「Docker for Windows」を使って、簡単に本来のWeb形式で見られるようにしました。
ということで今回は「Docker for Windows」を使って「PukiWiki」を見られるようにする方法をご紹介します。
この記事の前提環境
この記事の前提環境は次のとおりです。
- Docker for Windowsが動く環境
※私の環境は「Windows 10 Home + WSL2」です。 - PukiWiki 1.5.0
なお、私が「Docker for Windows」を導入したころの「Windows10 Home」には「WSL2」が入っていませんでした。
ですが、「Windows10 Home」で「Windows Insider Program」に参加すると、 「WSL2」が入れられたのです。
「Windows Insider Program」について次の記事があります。
※個人的には「Windows Insider Program」はオススメできませんが、ご参考頂ければ嬉しいです。
intellista.hatenablog.com
Dockerについて
「Docker」をご存知ですか?
「Docker」とはコンテナ型の仮想環境によりアプリケーションを開発・配置・実行するプラットフォームです。
仮想VM(Virtual Machine)のように物理マシンを仮想化するのではなく、「Docker」はもっと小さな単位(アプリケーション単位、サーバ単位、など)で仮想化します。
前者はハードも含めて仮想化しますが、後者はハードは仮想化せず共有します。
前者に比べて後者はとにかく軽量です。
そのため、近年の台頭がめざましいです。
私はすでに台頭してから知りました。
図書館でとてもわかり易くシンプルな書籍に出会い、ひとりハンズオンしました。
次の「自宅ではじめるDocker入門」という本です。
自宅ではじめるDocker入門 [改訂版] (I/O BOOKS)

この本でひととおりのDockerの操作(Docker Composeも含む)まで習得できました。
説明も例もシンプルかつわかりやすく、本当に助かりました。
ちなみに、「Docker」を使わずにホストOSにそのままPHPやWebサーバをインストールしても、この記事の目的は果たせます。
ですが、あえて「Docker」を使った理由は、次の2点です。
- ホストOSの環境をできるだけシンプルに保ちたい(いろいろ入れると不安定になりやすい)ため
- 環境のコピー、バックアップ、引っ越しが超簡単なため
※定義ファイルとPukiWiki一式のファイルコピーだけでOK
Dockerを使ってPukiWikiを簡単に見られるようにする方法
Dockerを使ってPukiWikiを簡単に見られるようにする手順を説明します。
フォルダ構成
次のフォルダ構成を前提に手順を説明します。
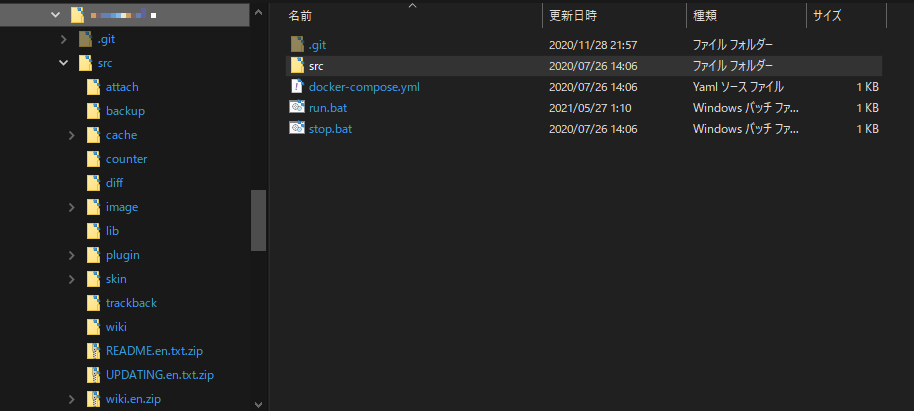
任意のフォルダ src docker-compose.yml
src配下に、PukiWikiの配布媒体を展開したもの(運用中のものでもOK)を入れます。
(私の場合は1.4.7を1.5.0にアップデートしたので、Updateファイルも入っていますが、なくても大丈夫です。 )
手順は3ステップだけ!
DockerでPukiWikiを見られるようにする手順は、たったの3ステップです。
- (1) 定義ファイルの作成
- (2) 起動バッチの作成と実行
- (3) ブラウザでアクセス
それでは順に見ていきます。
(1) 定義ファイルの作成
まず、Dockerのコンテナの定義ファイルを作ります。
次の内容のファイルを作り、docker-compose.ymlというファイル名で保存します。
version: "3"
services:
web-container:
image: php:5.5-apache
volumes:
- ./src/:/var/www/html/
ports:
- 8088:80
expose:
- 80このファイルはDockerの各地機能であるDocker Composeという機能の定義ファイルです。
次のようなことを定義しています。
(2) 起動バッチの作成と実行
次のコマンドをバッチファイルにして、実行します。
docker-compose up -d pause
このコマンドの意味は、同じフォルダにある定義ファイル((1)で作ったもの)を読み込んで、定義内容を実行する、という意味です。
実行すると、次のようになります。

ついでに停止バッチも作っておきましょう。
中身は次の通りです。
docker-compose stop docker-compose rm pause
ところで、起動バッチを実行すると、コマンドプロンプトに次のようなエラーが出る場合があります。
error while creating mount source path '/host_mnt/Users/~': mkdir /host_mnt/Users/~: file exists
例えば、次のような感じです。
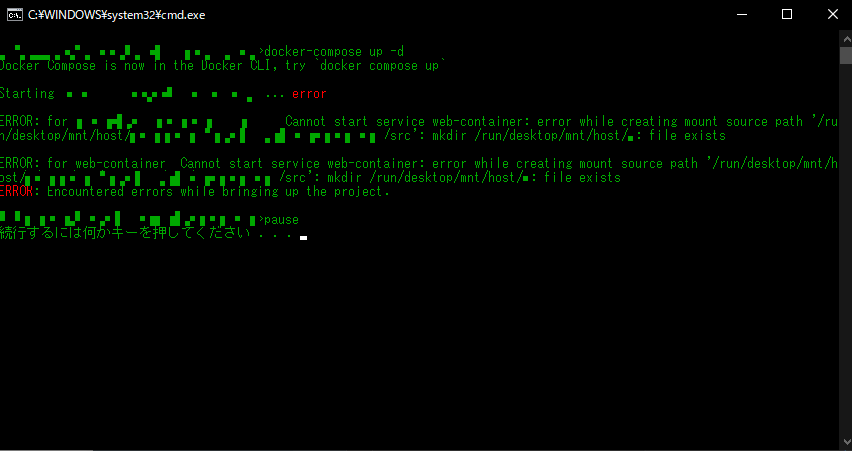
この場合、上記のURLにアクセスしてもトップページは表示されません。
こんな時は、タスクトレイのDockerアイコンからメニューをたどり、Dockerを再起動すると直るようです。
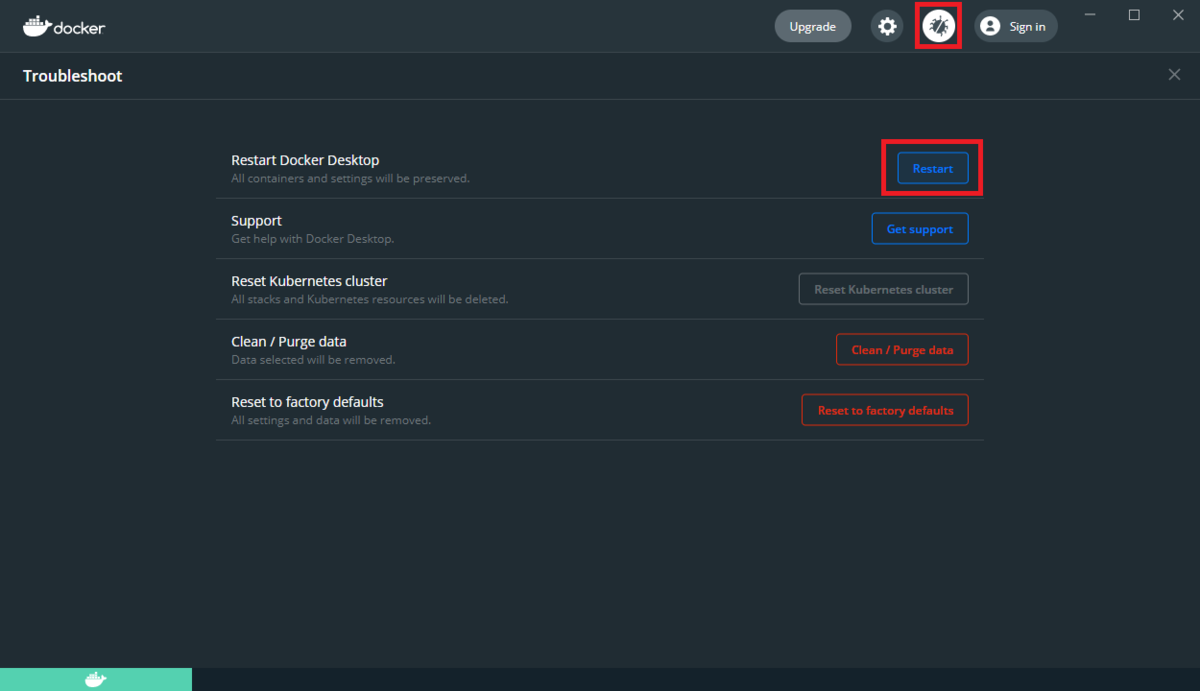
私の場合、再起動してバッチファイルを実行し直すと、エラーは解消しました。
なお、バッチファイルにするのは必須ではありません。
しかし、毎回同じコマンドを打つくらいなら、たとえ簡単なコマンドでもバッチファイルにしたほうが効率的です。











